
Tutorial Install Qwen3.5:latest di Ubuntu 22.04 dengan vGPU Nvidia L40S 16GB
Disclosure: artikel ini dapat memuat rekomendasi tools atau tautan afiliasi/sponsor di masa depan. Baca disclosure afiliasi.
Tutorial Install Qwen3.5:latest di Ubuntu 22.04 dengan vGPU Nvidia L40S 16GB
Artikel ini membahas cara menjalankan qwen3.5:latest lewat Ollama di Ubuntu 22.04 dengan dukungan vGPU Nvidia L40S 16GB, RAM 32GB, dan storage 200GB.
1. Cek Kesiapan Sistem
- Cek GPU dengan
nvidia-smi. - Cek RAM dengan
free -h. - Cek storage dengan
df -h.
2. Install Driver NVIDIA Jika Belum Ada
- Jalankan
sudo apt update. - Lihat driver yang direkomendasikan dengan
sudo ubuntu-drivers devices. - Install otomatis dengan
sudo ubuntu-drivers autoinstall. - Reboot server jika perlu.
3. Install Ollama
Install Ollama dari halaman resmi ollama.com/download. Setelah selesai, pastikan service aktif dengan systemctl status ollama.
4. Download dan Jalankan Model
- Download model:
ollama pull qwen3.5:latest - Jalankan model:
ollama run qwen3.5:latest
5. Cek Model yang Sudah Di-download
Untuk menampilkan model yang sudah ada di mesin Anda, jalankan ollama ls. Pada beberapa versi Ollama, perintah yang umum dipakai adalah ollama list.
6. Cek Model yang Sedang Berjalan
Untuk melihat model yang sedang aktif, jalankan ollama ps.
7. Ilustrasi Alur Ollama
Setelah Ollama terpasang, jalankan perintah ollama di terminal. Biasanya akan muncul tampilan interaktif dengan menu seperti Chat with a model dan daftar model yang tersedia. Jika Anda memasang lebih dari satu model, model lokal atau model cloud yang didukung bisa tampil di daftar itu sesuai instalasi dan ketentuan masing-masing, termasuk model gratis yang punya batasan pemakaian.
- Jalankan
ollamauntuk membuka menu interaktif. - Pilih salah satu model dari daftar.
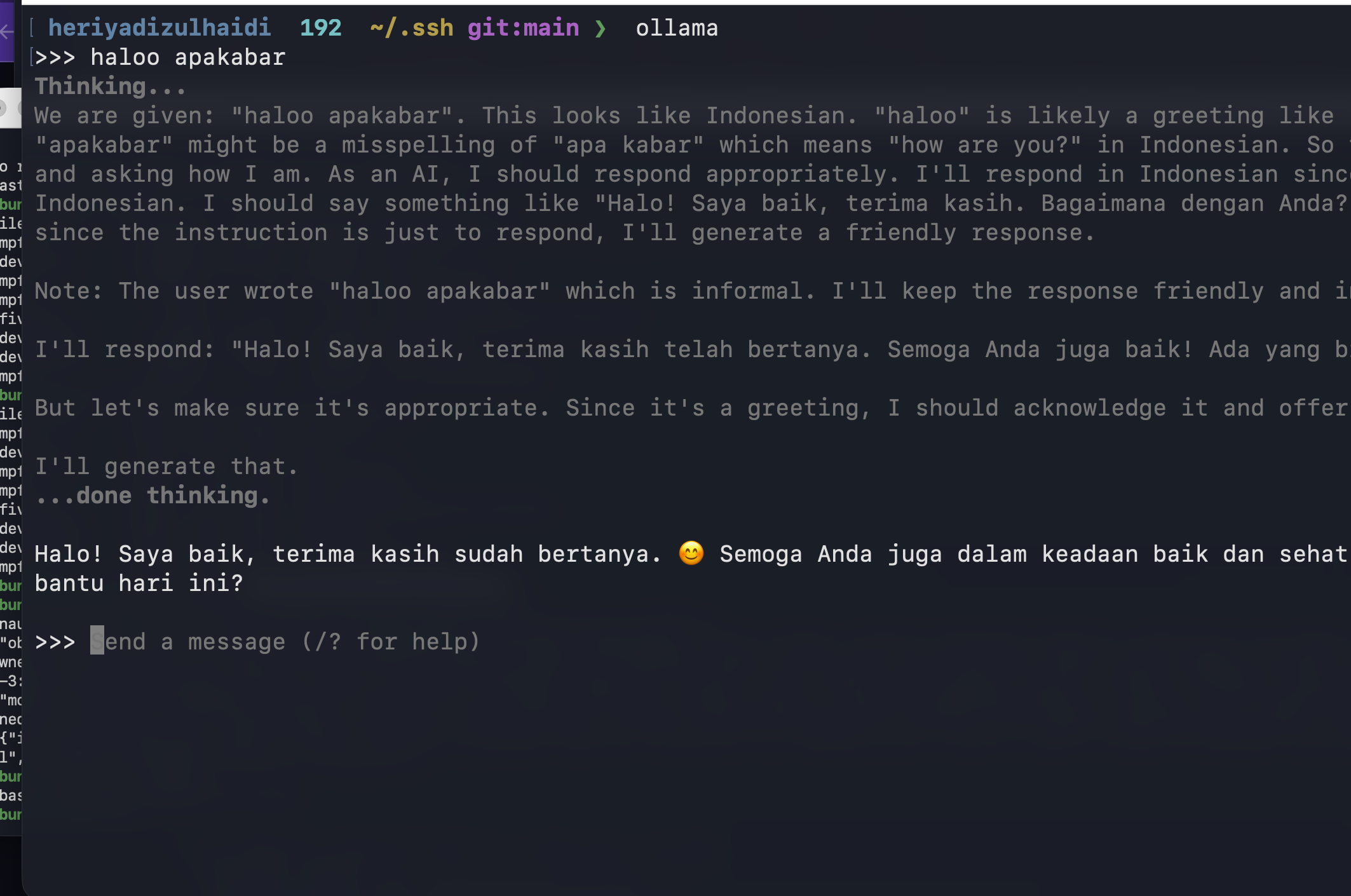
- Ketik pesan seperti
haloo apakabar. - Model akan merespons di terminal.
- Gunakan
ollama lsuntuk melihat model yang sudah di-download danollama psuntuk melihat model yang sedang berjalan.
Contoh tampilan respon Ollama:
8. Tips Tuning untuk L40S 16GB
- Gunakan satu model utama dulu.
- Jaga storage tetap lega.
- Batasi model aktif jika perlu dengan
OLLAMA_MAX_LOADED_MODELS=1. - Fokus ke stabilitas sebelum mengejar ukuran model yang lebih besar.
9. Korelasi Ukuran Model dan GPU
Ukuran file model di disk dan kebutuhan VRAM GPU itu tidak selalu sama, tetapi umumnya berkaitan. Makin besar model, makin besar pula beban memori saat dijalankan. Karena itu, L40S 16GB lebih aman untuk model kecil sampai menengah, terutama jika model sudah di-quantize.
- Model kecil: biasanya paling lancar di GPU terbatas dan cepat untuk chat harian.
- Model menengah: cocok untuk L40S 16GB jika tidak membuka banyak model bersamaan.
- Model besar: bisa butuh VRAM lebih dari 16GB atau perlu quantization agar muat.
- File model di disk: makin besar ukuran file, makin besar juga kebutuhan storage untuk download, cache, dan update.
Aturan praktisnya: kalau VRAM GPU penuh, model akan melambat atau gagal jalan. Kalau storage sempit, model mungkin tidak bisa diunduh atau disimpan dengan nyaman.
10. Kapan Setup Ini Cocok?
- Belajar model lokal di Ubuntu.
- Server internal yang butuh AI privat.
- Coding assistant offline yang ringan.
- Eksperimen workflow AI tanpa biaya API cloud.
Kesimpulan
Dengan Ubuntu 22.04, vGPU Nvidia L40S 16GB, RAM 32GB, dan storage 200GB, Anda sudah punya basis yang bagus untuk menjalankan qwen3.5:latest lewat Ollama.
Persiapan Server
Sebelum menginstall Qwen3.5, pastikan server Ubuntu 22.04 Anda siap: (1) Update sistem: <code>sudo apt update && sudo apt upgrade -y</code>. (2) Install driver NVIDIA: <code>sudo apt install nvidia-driver-550</code> (atau versi terbaru). (3) Verifikasi GPU: <code>nvidia-smi</code> — pastikan L40S atau GPU Anda terdeteksi. (4) Install CUDA toolkit: <code>sudo apt install nvidia-cuda-toolkit</code>. (5) Verifikasi CUDA: <code>nvcc –version</code>.
Disarankan menggunakan Ubuntu Server 22.04 LTS minimal (tanpa GUI) untuk menghemat resource. Pastikan RAM sistem minimal 32GB (16GB untuk sistem + 16GB untuk model). Gunakan SSD NVMe untuk penyimpanan model agar loading lebih cepat. Siapkan swap file 32GB sebagai cadangan jika terjadi OOM.
Instalasi Ollama dan Qwen3.5
Install Ollama di Ubuntu dengan: <code>curl -fsSL https://ollama.com/install.sh | sh</code>. Script akan menambahkan repository Ollama, menginstall package, dan memulai service. Verifikasi: <code>ollama –version</code> dan <code>systemctl status ollama</code>. Download Qwen3.5 versi terkuantisasi: <code>ollama pull qwen3.5:7b-q4_K_M</code>. Tunggu hingga selesai (tergantung kecepatan internet, biasanya 5-15 menit untuk ~4.5GB).
Untuk vGPU (virtual GPU), pastikan NVIDIA vGPU driver terinstall. L40S dengan vGPU mendukung partitioning hingga 4 instance. Alokasikan minimal 16GB per instance untuk Qwen3.5 7B Q4_K_M. Cek dengan <code>nvidia-smi -q -d GPU</code> untuk melihat konfigurasi vGPU. Jika menggunakan container Docker, pastikan GPU di-passthrough dengan benar ke container.
Optimasi untuk vGPU
vGPU punya overhead dibanding GPU fisik. Optimasi tambahan: (1) Pastikan host driver vGPU adalah versi terbaru. (2) Alokasikan VRAM 2-4GB lebih dari kebutuhan model sebagai buffer. (3) Nonaktifkan sharing GPU antar VM yang tidak perlu. (4) Gunakan MIG (Multi-Instance GPU) jika tersedia di GPU Anda. (5) Monitor performa vGPU dengan <code>nvidia-smi vgpu</code>. (6) Jika performa tidak memuaskan, pertimbangkan GPU dedicated.
Setelah install, uji coba dengan prompt sederhana: <code>ollama run qwen3.5:7b-q4_K_M "Jelaskan AI dalam 3 kalimat"</code>. Jika berjalan lancar, Anda siap menggunakan Qwen3.5 untuk berbagai aplikasi AI lokal.
Panduan Praktis Menggunakan Tutorial Install Qwen3.5:latest di Ubuntu 22.04 dengan vGPU Nvidia L40S 16GB
Bagian ini menambahkan konteks praktis agar pembaca tidak hanya mengetahui nama tools, tetapi juga memahami kapan tools ini sebaiknya dipakai, kapan sebaiknya dihindari, dan bagaimana cara mengevaluasi hasilnya. Untuk pemula, pendekatan paling aman adalah mulai dari satu kasus penggunaan kecil: meringkas dokumen, membantu menulis draft, membuat kode sederhana, atau menyusun ide kerja. Setelah hasilnya konsisten, barulah tools dapat dimasukkan ke workflow yang lebih penting.
Sebelum memakai tools AI dalam pekerjaan nyata, pastikan Anda memahami tiga hal: jenis data yang boleh dimasukkan, kualitas output yang diharapkan, dan cara memeriksa ulang hasilnya. Jangan memasukkan data rahasia perusahaan, data pelanggan, dokumen kontrak, atau kredensial sistem ke layanan AI publik kecuali kebijakan organisasi memang mengizinkannya.
Contoh Workflow yang Disarankan
- Riset awal: minta AI membuat daftar poin penting, lalu verifikasi dengan sumber resmi.
- Drafting: gunakan AI untuk membuat struktur artikel, email, laporan, atau kode awal.
- Review: minta AI mencari kelemahan, bug, asumsi yang belum terbukti, atau bagian yang terlalu ambigu.
- Finalisasi: manusia tetap memutuskan versi akhir, terutama untuk konten publik, keputusan bisnis, dan kode produksi.
Dengan alur seperti ini, tools AI menjadi asisten produktivitas, bukan pengganti penilaian manusia. Cara ini juga membantu mengurangi risiko hallucination, jawaban terlalu percaya diri, dan kesalahan teknis yang sering muncul pada penggunaan AI tanpa review.
Checklist Evaluasi Tools AI
Gunakan checklist berikut sebelum memilih tools AI untuk pemakaian rutin: apakah hasilnya konsisten dalam beberapa percobaan, apakah dokumentasinya jelas, apakah harga sesuai kebutuhan, apakah ada batasan privasi, apakah mendukung bahasa Indonesia, dan apakah mudah diintegrasikan ke workflow Anda. Jika tools digunakan untuk coding, tambahkan pengecekan test otomatis, review manual, dan version control agar perubahan dapat dilacak dengan aman.
Lanjut Belajar AI
Jika artikel ini membantu, lanjutkan ke materi terstruktur agar pemahaman AI lebih rapi dan praktis.



